8 грубых SEO-ошибок на illustrators.ru
Для хороших людей ничего не жалко. Именно таким принципов я руководствовался, когда придумывал новую рублику для блога. Назовем ее «Учимся на ошибках». Иногда у меня появляется возможность, время и желание подробно рассказать об ошибках, интересного сайта. Начнем мы рубрику с сайта illustrators.ru. Это большой и интересный проект для творческих людей. И как только начинаешь смотреть на состояние SEO у сайта, сразу понимаешь насколько творческих)
Данная статья не является полноценным поисковым аудитом сайта. Она описывает некоторые важный ошибки на сайте и предлагает пути их решения.
SEO-ошибки сайта illustrators.ru
1. Не полное использование ЧПУ
Многие страницы на сайте имеют вид illustrators.ru/?type=product, то есть содержат знаки вопроса и другие символы, которые могут двояко восприниматься поисковыми системами. Символы в адресах страниц делают возможными любые сочетания параметров. Такая адресация препятствует правильной индексации сайта, поскольку в индексе поисковой системы образуется большое количество страниц-дублей, связанных с тем, что параметры могут переставляться или менять свой состав. Кроме того, поисковые машины умеют различать динамические и статические URL’ы и определенным образом ограничивают число индексируемых страниц сайта с динамическими адресами.
Важная задача SEO — максимально избежать ситуации, когда интерпретация ссылок или текстов на сайте отдается на сторону поисковика. Если мы заранее устанавливаем все правила игры на своем сайте, то не только упрощаем жизнь поисковому роботу, но и минимизируем ошибки при попадании страниц в индекс поисковой системы.
Решение: Проработка логики структуры проекта и полный переход сайта на ЧПУ. Исключение из URL’ов все специальные символы, такие как «?», «=», «&» и др.
2. Пустой файл robots. txt
По наличию этой проблемы можно судить, что с проектом по SEO никто и никогда не работал. Даже начинающие оптимизаторы знают, что работа с файлом http://illustrators.ru/robots.txt — это залог правильной индексации страниц поисковыми системами.
Как файл выглядит на данный момент:
# See http://www.robotstxt.org/robotstxt.html for documentation on how to use the robots.txt file # # To ban all spiders from the entire site uncomment the next two lines: # User-agent: * # Disallow: / Sitemap: http://www.illustrators.ru/sitemap/sitemap.xml.gz
Необходимо обязательно его заполнить правильными директивами для поисковых роботов. Обязательно запретить для индексации разделы, которые не нужны пользователям. Как правило это разного рода технические страницы. Также я всегда рекомендую добавлять в файл вот такие директивы (только для сайтов с ЧПУ):
Disallow: /*?_openstat= Disallow: /*?gclid= Disallow: /*?utm_source= Disallow: /*from=adwords
Они позволяют решить важную проблему — попадание рекламных меток в индекс поисковых систем и замусоривание индекса.
3. Дубли страниц в индексе поисковых систем
На сайте изобилуют дубли страниц. Например в Яндексе одна и та же страница имеет разные адреса:
illustrators.ru/?page=1&sort_by=premium
illustrators.ru/?sort_by=premium
И оба URL участвуют в поиске и конкурируют между собой. Это естественно приводит к падению трафика. И чем больше дублей, тем больше падение. Эта проблема появилась как следствие отсутствия ЧПУ, так и следствие пустого файла robots.txt. При этом на сайте могут быть и другие дубли, которые тоже необходимо закрыть от индексации или удалить.
Решение: После внедрения ЧПУ, провести поиск дублей и удалить их либо техническими средствами (через CMS), либо через robots.txt.
4. Серьезная разница между количество страниц в поиске Яндекс и Google
Типичная проблема сайтов, которыми никто не занимается с точки зрения SEO. Она имеет разные причины, но всегда работает как лакмусовая бумажка: «если есть расхождение, значит с что-то не так».
Для illustrators.ru проблема существенна.
В индексе Яндекса: 1 000 000+ страниц
В индексе Google: 289 000 страниц
5. Лишние страницы в индексе
illustrators.ru является хорошим примером для изучения SEO-ошибок. Например в индексе Яндекса содержатся страницы листинга каталога работ на сайте. Обычно такие страницы отличаются друг от друга только составом карточек иллюстраций и не несут пользы для пользователя и поисковой системы. Хотя эти страницы могут и не являться дублями, но так как они не несут пользы, значит должны быть удалены из поискового индекса, чтобы не создавать избыточную SEO-конкуренцию для родительской страницы (обычно это первая страница листинга).
В частности это страницы:
illustrators.ru/?page=30
illustrators.ru/?page=12
illustrators.ru/?page=8

Пример лишних страниц листинга illustrators.ru в индексе Яндекса
6. Отсутствие семантического ядра и мета-тегов
Работу над любым SEO-проектом надо начинать с составления базового семантического ядра. Уже далее отталкиваясь от этого ядра оптимизируются тексты и мета-теги страниц или разделов сайта. Большинство сайтов делаются без участия оптимизатора. Это плохо, но не смертельно. Приходя на проект оптимизатор в любом случае составим сем. ядро и будем с ним работать.
Говоря об illustrators.ru можно смело сказать что ядра у проекта нет и мата-теги заполнялись по методу «как нравится». Для такого крупного сайта это равносильно потере десятков тысяч посещений ежемесячно.
Пример.
На многих страницах нет заголовков H1, наполненных ключевыми словами. Эти теги определяют содержание страницы не только для пользователя, но и для поисковой системы. Создание и заполнение заголовков H1 — это основа оптимизации сайта. На страницах:
illustrators.ru/illustrations/1 087 613
illustrators.ru/users/oliya-panina
тег отсутствует, а мог бы например быть названием работы, которое ей придумал сам автор. При этом название работы на сайте есть, но его оформление в коде вызывает вопросы.
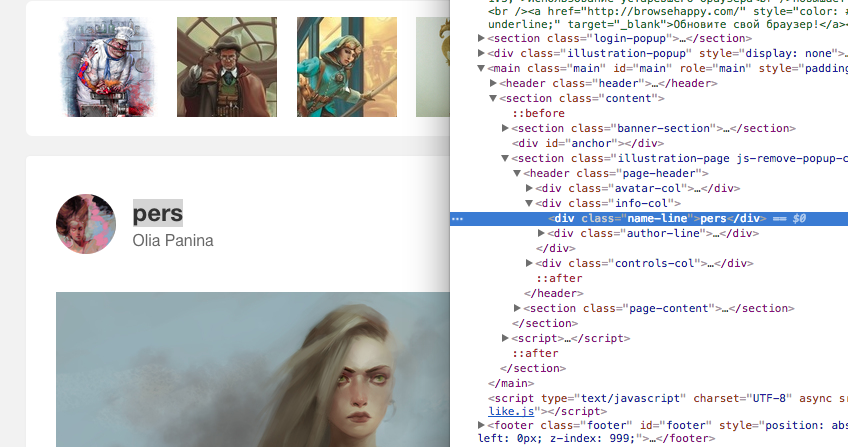
Пример отсутствия мета-тега H1 на сайте illustrators.ru
7. Однотипные и неинформативные мета-теги
Важной проблемой для крупных проектов является не только их наличие или отсутствие в поиске, но и то как выглядят их поисковые сниппеты.
Сниппет — это блок информации о найденном документе, который отображается в результатах поиска. Сниппет состоит из заголовка и описания или аннотации документа, а также может включать дополнительную информацию о сайте.
Подробнее на Яндексе
Сейчас в поиске illustrators.ru выглядит мягко говоря недостаточно выразительно. Это приводит к тому что пользователь не понимает куда кликать и понижается CTR страниц в выдаче, а значит и сайт получает меньше трафика.
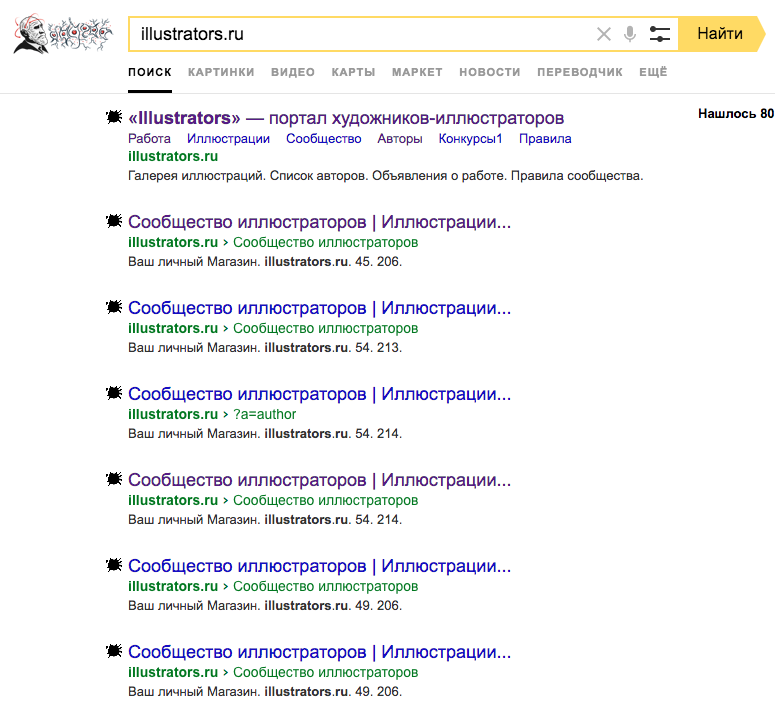
Пример однотипных сниппетов illustrators.ru в Яндексе
Решение: Придумать различные сниппеты для разных типов страниц. Заполнить мета-теги TITLE и DESCRIPTION. Переработать шаблон заполнения мета-тегов. Внедрить на сайт семантическую разметку для творческих работ
8. Отсутствует заголовок Last-Modified
Для крупных сайтов важно отдавать на индексирование поисковикам только нужные страницы. Если поисковая система запрашивает страницу, а она не изменялась с предыдущего запроса, то нужно отдать не ответ"200 OK", а ответ"304 Not Modified". И поисковый робот не будет загружать страницу и обновлять ее в индексе. Чтобы это работало на сайте надо использовать HTTP заголовок Last-Modified.
В чем польза для SEO?
Всегда работает правило: 100 страниц будут загружаться и индексироваться поисковиками быстрее чем 1000. Мы облегчаем работу роботам и даем им в первую очередь нужные нам страницы. Настройка заголовка Last-Modified и обработка заголовка If-Modified-Since нужна всем без исключения крупным сайтам. Особенно это важно для проектов, у которым контент обновляется ежедневно: СМИ, социальные сети, различные агрегаторы. Подробнее о том как работает этот инструмент, читайте в статье: Как ускорить индексацию новых страниц в разы. Last-Modified и If-Modified-Since.
Вместо заключения
Ошибок на сайте много и это в целом нормально для сайта, который никто не оптимизировал. Все можно исправить, все можно наверстать. Надеюсь мои рекомендации помогут ребятам улучшить проект и покорить новые высоты. Учитесь на чужих ошибках. Это тяжело, но окупится результатами.
Задавайте вопросы, подписывайте на рассылку блога и на мой канал в Telegram!